Markdown is a very simple, yet efficient format for editing text-based content. The TAG Neuron converts Markdown to HTML automatically when web browsers download it, making it a powerful tool for publishing online content. The syntax is inspired by the original markdown syntax as defined by John Gruber at Daring Fireball, but contains numerous other additions and modifications. Some of these are introduced in the TAG Neuron, others are inspired by selected features used in MultiMarkdown and Markdown Extra. Below, is a summary of the markdown syntax, as understood by the TAG Neuron.
Note: You can use the Markdown Lab to experiment with Markdown syntax.
Markdown includes a series of simple syntax constructs, categorized into different types. Inline constructs are constructs that can be used in normal text flow. The follow subsections show available inline constructs that can be used to enhance the text.
Text formatting
In Markdown it’s easy to format text. Special characters are used around the text you want to format, as is shown in the following subsections.
Emphasized text
To emphasize text, enclose the text using asterisks *, such as this: *Emphasized text*. In HTML, this becomes: Emphasized text. Emphasized text can be included in the middle of a sentance, or in the middle of a word. In HTML, emphasized text gets surrounded by <em> and </em> tags.
Strong text
Strong text is included by surrounding it with double asterisks **. Example: **Strong text**. Result: Strong text. As with emphasized text, it can be included in the middle of a sentance, or in the middle of a word. In HTML, strong text gets surrounded by <strong> and </strong> tags.
Underlined text
Underlined text is created by surrounding the underlined text with underscores _. Example: _Underlined text_. This is transformed to: Underlined text. As with other text formatting operators, underlined text can be included in the middle of a sentance, or in the middle of a word. In HTML, underlined text gets surrounded by <u> and </u> tags.
Superscript text
You can add superscript text by inserting the superscript text between a ^[ and a ], or a ^( and a ). If you want to use parenthesis ( or ) in your superscript text, you should use ^[ and ]. You could also escape the parenthesis using \( or \). Some special characters, like the digits and ASCII letters can superseed the ^ sign without having to be enclosed in parenthesis or brackets. See Typographical enhancements for details.
Examples:
Some^[superscript] ⇒ Somesuperscript
a^[b+c]=a^ba^c ⇒ ab+c=abac
a^2+b^2=c^2 ⇒ a²+b²=c²
a^n+b^n<>c^n, n>=3 ⇒ an+bn≠cn, n≥3
a^[(b+c)/2]=sqrt(a^ba^c) ⇒ a(b+c)/2=sqrt(abac)
a^(\(b+c\)/2)=sqrt(a^ba^c) ⇒ a(b+c)/2=sqrt(abac)
Subscript
Text between brackets [ and ], that do not form part of a link, a link reference, reference definitions or a multi-media definition or reference, is treated as subscript text. Examples:
Some[subscript] ⇒ Somesubscript
a[i]=A[i,j] ⇒ ai=Ai,j
Inserted text
Inserted text, which by default is also shown as underlined (but which can be changed to a different style using style sheets), is created by surrounding the inserted text with double underscores __. Example: __Inserted text__. This becomes: Inserted text. As with the operators above, inserted text can be included in the middle of a sentance or in the middle of a word. In HTML, inserted text gets surrounded by <ins> and </ins> tags.
Strikethrough text
Strikethrough text is created by surrounding its text using tildes ~. Example: ~Strikethrough text~. This is transformed to: Strikethrough text. As with the other text formatting operators, it can be included in the middle of a sentance or in the middle of a word. In HTML, strikethrough text gets surrounded by <s> and </s> tags.
Deleted text
Deleted text, which by default is also shown as strikethrough text (but which can be changed to a different style using style sheets), is created by surrounding the inserted text with double tildes ~~. Example: ~~Deleted text~~- Result: Deleted text. As with the operators above, deleted text can be included in the middle of a sentance or in the middle of a word. In HTML, inserted text gets surrounded by <del> and </del> tags.
Inline code
Inline code can be used to include code into flowing text. To include inline code, surround it using single or double back ticks `, as shown in the following example: `Inline code`. This is transformed to: Inline code. As with other text formatting operators, inline code can be included in the middle of a sentance or in the middle of a word. In HTML, inserted text gets surrounded by <code> and </code> tags.
Note: Characters that have special meaning in markdown, such as *, _, ~, etc., are shown as normal characters in inline code.
Note 2: If you want to include a back tick in the inline code, you can surround the inline code using double back ticks and a space, one after the first double back tick, and one before the last back tick, such as this: `` `Inline code` ``. This sequence was used to produce `Inline code`.
Links
To include a link into a markdown text, you can, apart from automatic links, also include custom links. These are written in the form [Text](URL) or [Text](URL "Title"). The text can include inline formatting, if desired. URLs can be absolute (include URI scheme) or local relative links (without URI scheme).
To facilitate writing text, and reusing links, it’s possible to use a reference instead of a direct URL in the link definition. This is done using brackets instead of parenthesis, with an optional space between the two sections, and a reference ID instead of the URL, as this: [Text][Reference] or [Text] [Reference]. References are case insensitive. It’s also possible to use an implicit reference identity. In this case, the second set of brackets is empty. The reference identity is taken to be the same as the text for the link.
The references can then be written anywhere in the document (apart from other text). There are various ways to writing link references. They begin on separate rows, and start with a the reference ID between brackets followed by a colon and then the link [ID]: URL. Optionally, the URL can be surrounded by angle brackets, as follows: [ID]: <URL>. The reference can also have an optional title. This title can follow the URL directly, or be written on the following row: [ID]: URL "Title". The title can be surounded between double quotes "Title", single quotes 'Title' or parenthesis (Title), the choice is up to the writer. While the references are visible in the markdown document, they will be removed, and not displayed in the generated HTML page.
The following list shows some examples. These examples are used above to create the links in the table.
Markdown help you include links to online resources (URLs) or mail addresses automatically by surrounding them with < and > characters, such as <http://example.com/> or <address@example.com>. These would turn into clickable links in the HTML representation, as follows: http://example.com/ and address@example.com.
Note: It’s important to include the URI Scheme (for example http://) in links or the @ sign in mail addresses, for the parser to understand it’s an automatic link or an address, and not another type of construct.
Automatic web links
The Markdown parser will create automatic links if your link is a web link, i.e. if it starts with http:// or https://. Example:
Note: Some of the multi-media interfaces supported, can also manage automatic links. If you include a web link that such a multimedia interface recognizes, the corresponding presentation will be used.
Abbreviations
You can define abbreviations in your text by writing links using the predefined abbr URI schema, as follows:
[LOL](abbr:Laugh out Loud) and [OMG](abbr:Oh My God) are two abbreviations commonly used in social networks.
Result:
LOL and OMG are two abbreviations commonly used in social networks.
Note: In HTML, the <abbr> tag is used. Instead of using the title attribute to present the definition, the data-title attribute is used. This allows the web designer to define how to present the definition, using CSS.
Hashtags
You can create hashtags in markdown by adding a hash character (#) followed by a sequence of letters and/or numbers. No space characters or punctuation marks are allowed. The main function of hashtags is to highlight keywords in a text. Applications can also use them to create spceial types of links. How such a link would work, is application-specific however, if it exists.
Note: Care has to be taken so that the end result is HTML compliant. While HTML can be inserted anywhere, it’s only useful if the markdown is used to generate HTML pages. If the markdown is used to generate other types of content, such as XAML, inline HTML will be omitted. Since inline HTML is used within block constructs, only span-level HTML constructs should be used.
Special characters in HTML
In HTML, certain characters are used to define certain constructs. This includes <, > and &. In markdown, you don’t have to escape these, unless they form part of a markdown construct, an HTML tag or an HTML entity. In all other cases, the markdown parser will escape them for you. So, you can write things such as “4<5”, and “AT&T", without having to escape the < into < and the & into &.
Escape character
If you want to use a character that otherwise has a special funcion in markdown, you can escape it with the backslash character \, to avoid it being interpreted as a control character. If you want to include a backslash character in your text, you need to escape it also, and write two \\.
The following table lists supported escape sequences. Characters not listed in this table do not need to be escaped.
Sequence
Result
Sequence
Result
Sequence
Result
Sequence
Result
Sequence
Result
\*
*
\{
{
\)
)
\-
-
\%
%
\_
_
\}
}
\<
<
\.
.
\=
=
\~
~
\[
[
\>
>
\!
!
\:
:
\\
\
\]
]
\#
#
\"
"
\|
|
\
`
\(
(
\+
+
\^
^
Note: Some characters only have special meaning in certain situations, such as the parenthesis, brackets, etc. The occurrence of such a character in any other situation does not require escaping.
Typographical enhancements
There are numerous typographical enhancements added to the markdown parser. This makes it easier to generate beautiful text. Some of these additions are are inspired by the the Smarty Pants addition to the original markdown, but numerous other character sequences have been added to the TAG Neuron version of markdown, as shown in the following table:
Emojis are supported, and included into the document using the shortname syntax :shortname:. You can provide more emphasis by using more colons before and after: ::shortname::, :::shortname:::, ::::shortname::::, etc., each resulting in a larger emoji:
Smileys are supported in markdown text, and converted to the corresponding emojis. For a list of supported smileys, click here.
HTML Entities
HTML Entities are supported in markdown text, and converted to the corresponding UNICODE characters. For a list of supported HTML entities, click here.
Block constructs
Block constructs are larger constructs representing larger blocks in the document. They are all separated from each other using empty rows (or rows including only white space characters). The following subsections lists the different block constructs that are available in the TAG Neuron version of markdown.
Paragraphs
Paragraphs are created by writing blocks of text and separating them with empty rows (or rows with only white space characters). They are placed within <p> and </p> in the generated HTML. Line breaks in your markdown text files are ignored by the markdown parser and interpreted as normal white space. The generated output will display all text in the paragraph as a continuous block of text, that will adapt itself to the width of the available display area.
Line breaks
If you want to include hard line breaks
in a paragraph, you must terminate the
rows you want to break with two space
characters.
Headers
Headers can be written in different ways, depending on what you prefer. A first level header can be written on one row, followed by a row of variable length, containing only equal characters (=), as follows:
First level header
========================
A second level header is written in a similar fashion, but instead of equal signs, hyphens (-) are used:
Second level header
------------------------
Headers can also be written on a single line, prefixing them with hash signs (#) and a space character. The number of hash signs defines the level of the header:
# First level header
## Second level header
### Third level header
#### Fourth level header
...
Note: If you omit the space character after the hash signs, you create a hashtag instead.
If using hash signs to define headers, you can suffix any number of hash signs at the end of the row for clarity in the markown. These will not be displayed in the generated output.
# First level header #######
## Second level header #####
### Third level header #####
#### Fourth level header ###
...
Note: Each header will be assigned a local id that you can link to. You can link to any header in a document, by adding a fragment, starting with the hash sign, and then followed by the automatically generated id. The id is formed by joining the words in the header together using lower case, capitalizing the first letter of each word except the first word which is kept all lower case. This is called Camel Casing, or camelCasing. To link to the “Block constructs” header above, for instance, you would write something like this:
Note also: You can easily add a Table of Contents constract to the document. It will automatically generate a table of contents in the output that will link to all headers available in the document using the automatically generated ids.
Block quotes
Block quotes are blocks of text, where each paragraph is prefixed by a > character and 1-3 space characters (or a tab character). Alternativly, each row in each paragraph of the block quote can be prefixed by the > character and white space, making the text look tidier. Block quotes allow nested constructs.
Example:
> A block quote can include other block quotes:
>
> > Like this one
>
> It can include tables:
>
> | a | b |
> |---|---|
> | 1 | 2 |
> | 3 | 4 |
> | 5 | 6 |
>
> Or code:
>
> 10 PRINT "*";
> 20 GOTO 10
>
> It can include lists:
>
> * Item
> 1. Sub item
> 2. Sub item 2
> * Item 2
>
> etc.
This is transformed into:
A block quote can include other block quotes:
Like this one
It can include tables:
a
b
1
2
3
4
5
6
Or code:
10 PRINT "*";
20 GOTO 10
It can include lists:
Item
Sub item
Sub item 2
Item 2
etc.
The > sign can be optionally prefixed by a + or a - sign to show the block has been inserted (+) or deleted(-). Example:
+> This paragraph has been added.
This paragraph is unchanged.
-> This paragraph has been deleted.
This is transformed to:
This paragraph has been added.
This paragraph is unchanged.
This paragraph has been deleted.
Bullet Lists
Bullet lists are created by simply writing the items prefixed by either asterisks *, plus signs + or minus signs (hyphens) -, followed by one to three space characters or a tab. If the items are written together, as in the following example, Each item will contain just inline text (including inline constructs):
* Normal text
* *Emphasized text*
* **Strong text**
This is displayed as:
Normal text
Emphasized text
Strong text
If the items are written with empty rows (or rows including only white space) separating them, the items are formatted as paragraphs:
+ Normal text
+ *Emphasized text*
+ **Strong text**
When displayed, this becomes:
Normal text
Emphasized text
Strong text
Items can span multiple paragraphs as well. In that case, separate the paragraphs, but make sure to indent at least the first row of each paragraph with 4 space characters, or a tab character. (Each row in the paragraph can be indented, to make the text look tidier, but this is not required.)
- This is the first item.
The first item is written using normal text.
- *This is the second item.*
The first item is written using emphasized text.
- *This is the third item.*
The third item is written using strong text.
This results in:
This is the first item.
The first item is written using normal text.
This is the second item.
The first item is written using emphasized text.
This is the third item.
The third item is written using strong text.
Numbered Lists
Numbered lists are created by simply writing the items prefixed by their corresponding number followed by a period . a space character. The number used will be the number that the item receives in the generated list. As with bullet lists, items written together are treated as inline text, while items separated by empty rows (or rows including only white space) will be treated as items containing paragraphs. Multi-paragraph items are indented. Example of a simple list:
1. Normal text
10. *Emphasized text*
100. **Strong text**
This becomes:
Normal text
Emphasized text
Strong text
An alternative exists to the fixed numbering scheme. Instead of writing the item number, the hash sign (#) can be used to create a lazy numbered list, as follows:
#. Normal text
#. *Emphasized text*
#. **Strong text**
This is shown as:
Normal text
Emphasized text
Strong text
All types of lists can be nested. The nesting level is kept track of using 4 space characters or 1 tab character per level. Example:
Definition lists can be used to create glossaries, or similar constructs where terms are defined. A definition list is divided into definition blocks. Each definition block can have one or more terms followed by a one or more descriptions. The terms are simple inline text, written one term per row. The descriptions are prefixed by a colon (:) on the first paragraph. If it has more than one paragraph, the first row (at least) each paragraph must be indented using 1-4 space characters or one tab character. If you want, you can indent all rows in the paragraphs, to make the text easier to read.
A simple definition list only contains a sequence of terms and simple definitions:
Term 1
: Definition 1
Term 2
: Definition 2
Term 3
: Definition 3
This becomes:
Term 1
Definition 1
Term 2
Definition 2
Term 3
Definition 3
You can group multiple terms for a definition:
Term 1
Term 2
: Definition for Term 1 and 2.
Term 3
: Definition 3
Which is transformed to:
Term 1
Term 2
Definition for Term 1 and 2.
Term 3
Definition 3
You can also have multiple descriptions for a single term:
Term 1
: Definition 1.1
: Definition 1.2
Term 2
: Definition 2
This is shown as:
Term 1
Definition 1.1
Definition 1.2
Term 2
Definition 2
As with the other forms of lists mentioned above, if you include an empty row (or a row with only whitespace) between terms and definitions, definitions are considered paragraphs instead of inline text.
Term 1
: Definition 1
Term 2
: Definition 2
Term 3
: Definition 3
Which is displayed as:
Term 1
Definition 1
Term 2
Definition 2
Term 3
Definition 3
You can also have long descriptions spanning multiple paragraphs, or join types, some of inline type, others of paragraph type.
Term 1
: Long Definition for term 1.
It continues to a second paragraph.
Term 2
: Definition 2
Which becomes:
Term 1
Long Definition for term 1.
It continues to a second paragraph.
Term 2
Definition 2
Task lists
Task lists are lists where items are either checked or unchecked. An unchecked item is prefixed using [ ] (note the single space character). Checked items are prefixed using [x] or [X]. As with bullet lists or numbered lists, items written together are treated as inline text, while items separated by empty rows (or rows including only white space) will be treated as items containing paragraphs. Multi-paragraph items are indented. Example of a simple task list:
[ ] Unchecked item
[x] Checked item
[ ] Unchecked subitem
[x] Checked subitem
[X] Another checked subitem
[X] A second checked item
This gets shown as:
Horizontal Alignment of text
You can control horizontal alignment of blocks in Markdown, by using combinations of << and >> around the contents of the blocks, as illustrated in the following sections. You can choose to put the << and >> operators on each row, or only on the first or last rows of each block correspondingly.
Note: For the following examples, you might need to decrease the width of the browser window, to properly see how text alignment works.
Left alignment of text
Add << at the beginning of each block, or at the beginning of each row in each block, to left-align the contents. Example:
<<##### Left-aligned Example
<<
<<This text is left-aligned. Left-alignment is done by placing `<<` in the beginning of each block, or each row in each block,
<<as appropriate.
This is shown as:
Left-aligned Example
This text is left-aligned. Left-alignment is done by placing << in the beginning of each block, or each row in each block, as appropriate.
Right alignment of text
Add >> at the end of each block, or at the end of each row in each block, to right-align the contents. Example:
##### Right-aligned Example>>
>>
This text is right-aligned. Right-alignment is done by placing `>>` at the end of each block, or each row in each block,>>
as appropriate.>>
This is shown as:
Right-aligned Example
This text is right-aligned. Right-alignment is done by placing >> at the end of each block, or each row in each block, as appropriate.
Center alignment of text
Add >> at the beginning of each block, or at the beginning of each row in each block, and << at the end of each block, or at the end of each row in each block, to center-align the contents. Example:
>>##### Center-aligned Example<<
>><<
>>This text is center-aligned. Center-alignment is done by placing `>>` in the beginning of each block, or each row in each block,<<
>>and `<<` at the end of each block, or at the end of each row in each block, as appropriate.<<
This is shown as:
Center-aligned Example
This text is center-aligned. Center-alignment is done by placing >> in the beginning of each block, or each row in each block, and << at the end of each block, or at the end of each row in each block, as appropriate.
Margin alignment of text
Add << at the beginning of each block, or at the beginning of each row in each block, and >> at the end of each block, or at the end of each row in each block, to margin-align the contents. Example:
<<##### Margin-aligned Example>>
<<>>
<<This text is margin-aligned. Margin-alignment is done by placing `<<` in the beginning of each block, or each row in each block,>>
<<and `>>` at the end of each block, or at the end of each row in each block, as appropriate.>>
This is shown as:
Margin-aligned Example
This text is margin-aligned. Margin-alignment is done by placing << in the beginning of each block, or each row in each block, and >> at the end of each block, or at the end of each row in each block, as appropriate.
Code blocks
If you want to include larger blocks of code, there are two ways to do this. In both cases you write the code, as-is, with empty rows before and after. You can choose to either indent each line of the code with 1-4 spaces or one tab characters:
10 PRINT "*";
20 GOTO 10
Or, you can write the code without special indentation, but beginning and ending the the block with rows consisting of three or more back ticks (```), as follows:
```
10 PRINT "*";
20 GOTO 10
```
Note that you can insert blank rows in code. Note also that you need to terminate the code block with the same amount of back ticks. The indentation in the first case, or the three (or more) back ticks in the second case, tell the parser when the code block ends. In both cases, you get the following result:
10 PRINT "*";
20 GOTO 10
If you want, you can specify the language the code was written in. By doing this, you activate the syntax highlighting feature provided by highlight.js. Example:
```basic
10 PRINT "*";
20 GOTO 10
```
This is transformed into:
10 PRINT "*";
20 GOTO 10
If the language begins with base64, and the contents is Base64-encoded UTF-8-encoded text, the corresponding text will be decided and displayed, where the language is whatever comes after base64. This method can be used to maintain literal content and syntax, especially if not aware at design time, and avoid conflicts with the Markdown parser. The following example shows how to present XML from script, in a readable manner, without interfering with the overall structure of the document:
Note: By default, the default.css highlight style is used on the page, if syntax highlighting using highlight.js is available. The library is accessible through the /Highlight web folder. You can control the style used for highlighting, by including a CSS: /Highlight/style/STYLE_NAME.css header at the top of the page, where STYLE_NAME refers to the actual style to use on the page.
Note 2: If you use back-ticks, you must use the same amount of back-ticks when closing the code block, as you did when opening the code block.
Note 3: You can embed code-blocks defined using back-ticks in code-blocks defined by back-ticks, if each embedded code-block uses fewer back-ticks compared to the parent block.
The TAG Neuron provides a pluggable architecture when it comes to rendering code blocks. Depending on the language, the code can be rendered in different ways. The following subsections illustrate such renderings.
Indentation of HTML
It is common to indent HTML code, to make it easier to track nesting of HTML elements on the page. Since HTML can be embedded into Markdown, it is important to be able to allow such HTML code without converting it to code blocks. For this reason, any indented paragraph that starts with a < character will be treated as indented HTML. Instead of rendering it as a code block, the indentation is simply removed, and the contents parsed as normal Markdown. However, if you want to explicitly show HTML in a code block, do not use the indentation method. Instead prefix the HTML with ```html, and a ``` at the end.
Example of indented HTML:
<div style="background-color: #f0f0f0; border: 1px solid #c0c0c0; padding: 10px; color: black;">
<p>
This is a paragraph of text, written in *Markdown*.
</p>
</div>
This renders as:
This is a paragraph of text, written in Markdown.
2D Layout diagrams
You can make the Markdown engine transform XML that conforms to the http://waher.se/Schema/Layout2D.xsd namespace directly to images, by placing it in a code block with language layout. The layout namespace is defined in the Waher.Layout.Layout2D library.
Example of a layout diagram (some parts have been removed for splicity; full example here: GitHub):
You can also place a layout graph definition in an .xml file and link to it from an IMG tag in your web pages. It will be automatically converted to an image, as requests from IMG tags request image content only. Example:
Results in:
If you embed the image in a Markdown page, you will need to add an additional image extension to the resource, to let the Markdown parser know you are embedding image content, and not some other form of content. That will explicitly convert the graph to an image of the requested type. The both cases, the graph will be converted to an image of the requested type when requested by the browser. Example:
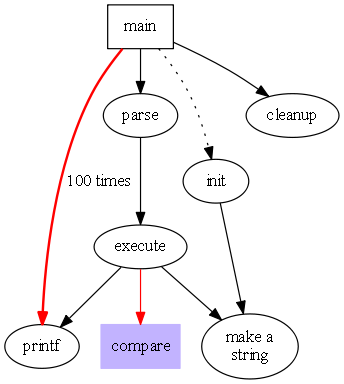
If GraphViz is installed on the same machine as the TAG Neuron, it can be used to render diagrams from code blocks. There are six diagram types: dot, neato, fdp, sfdp, twopi and circo. Use the corresponding diagram type as language for the code block. The diagram type can be suffixed by a colon : and a title. The diagram will be rendered as an SVG image.
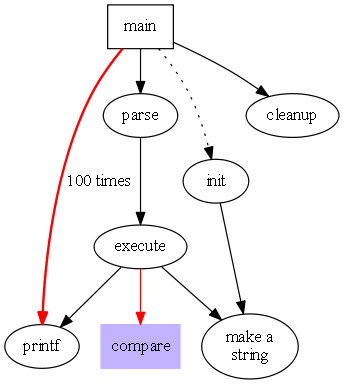
Example of a dot GraphViz diagram:
```dot: Fancy graph
digraph G {
size="4,4";
main [shape=box]; /* this is a comment */
main -> parse [weight=8];
parse -> execute;
main -> init [style=dotted];
main -> cleanup;
execute -> { make_string; printf}
init -> make_string;
edge [color=red]; // so is this
main -> printf [style=bold,label="100 times"];
make_string [label="make a\nstring"];
node [shape=box,style=filled,color=".7 .3 1.0"];
execute -> compare;
}
```
This is rendered as:
Fancy graph
Note: If after having installed GraphViz, the above is not displayed as a graph, make sure to restart the TAG Neuron service (or the machine). GraphViz is detected during initialization of the service. Make sure that GraphViz is installed in the program data folder, preferrably in its default folder.
Note 2: You can make the graph clickable by embedding URL attributes on either nodes, edges or the entire graph.
Note 3: You can use the GraphViz Lab to experiment with GraphViz syntax.
You can also place a GraphViz graph definition in a .dv or .dot file and link to it from an IMG tag in your web pages. It will be automatically converted to an image, as requests from IMG tags request image content only. Example:
Results in:
If you embed the image in a Markdown page, you will need to add the extension .png or .svg to the resource, to let the Markdown parser know you are embedding image content, and not some other form of content. That will explicitly convert the graph to an image of the requested type (i.e to PNG or SVG formats). The both cases, the graph will be converted to an image of the requested type when requested by the browser. Example:
If you have the PlantUML.jar file stored in the program files folder, and have Java installed on the same machine as the TAG Neuron, they can be used to render UML diagrams from code blocks. The diagram will be rendered as an SVG image.
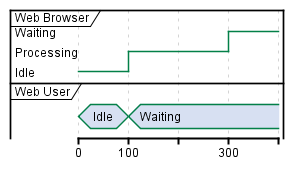
Example of a sequence uml PlantUML diagram:
```uml: Simple Sequence diagram
@startuml
Alice -> Bob: Authentication Request
Bob --> Alice: Authentication Response
Alice -> Bob: Another authentication Request
Alice <-- Bob: another authentication Response
@enduml
```
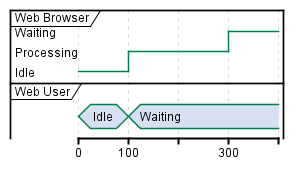
```uml: Simple Timing diagram
@startuml
robust "Web Browser" as WB
concise "Web User" as WU
@0
WU is Idle
WB is Idle
@100
WU is Waiting
WB is Processing
@300
WB is Waiting
@enduml
```
This is rendered as:
Simple Sequence diagramSimple Timing diagram
Note: If after having installed PlantUML and Java, the above is not displayed as a graph, make sure to restart the TAG Neuron service (or the machine). PlantUML and Java are detected during initialization of the service. Make sure that PlantUML is installed in the program data folder.
Note 2: You can use the PlantUML Lab to experiment with PlantUML syntax.
You can also place a PlantUML graph definition in a .uml file and link to it from an IMG tag in your web pages. It will be automatically converted to an image, as requests from IMG tags request image content only. Example:
Results in:
If you embed the image in a Markdown page, you will need to add the extension .png or .svg to the resource, to let the Markdown parser know you are embedding image content, and not some other form of content. That will explicitly convert the graph to an image of the requested type (i.e to PNG or SVG formats). The both cases, the graph will be converted to an image of the requested type when requested by the browser. Example:
You can embed an image directly into the Markdown by placing the BASE64-encoded version of the image, together with its image Content-Type, in side a code block.
You can embed a PDF document directly on the Markdown page using a code block, in a way similar to embedding images. You include the BASE64-encoded contents of the PDF document into the code block, and ensure you use the Internet Content-Type application/pdf for PDF as the language of the code block.
This will result in an embedded object being rendered in HTML, displaying the contents of the PDF document, if the browser supports embedding documents in HTML 5.
You can also embed PDF documents using the multimedia construct, as shown in the following example:

This results in the document being embedded as follows:
Multimedia
Multimedia items are defined in a similar way as links in a markdown document. They can both be defined inline, or by reference, as links are too. Four things differ, between multimedia links and normal links:
The link to a multimedia item must be prefixed by an exclamation mark (!).
The definition can have an optional WIDTH and HEIGHT value after the optional title. Both are positive integers, and both can be provided in both the inline version and the referenced version.
The URL the link is pointing to, selects the best multimedia interface.
It is possible to define multi-resolution or multi-format multimedia content items, by listing a sequence of URLs pointing to resources of different sizes and formats. If the multimedia interface supports multi-format or multi-resolution content, all these resources will be used. If the interface only supports a single source, the first source in the definition will be used. Examples of multi-resolution and multi-format content items will be given below.
Developers on the platform can add their own multimedia interfaces. All they need to do is implement a class with a default constructor, that implements the Waher.Content.Markdown.Model.IMultimediaContent interface. The parser will find the class and instantiate it, and then use it for content that it matches. The multimedia interfaces described below only cover the interfaces that are included by default.
Note: If no particular multimedia handler is found for a URL, it is considered to be an image by default.
Images
An image can both be included inline, in flowing text, or standalone in a separate block. In the latter case, it’s rendered as a figure, with a figure caption. To include an image inline, you can do as follows:
This is an inline image: 
This will be displayed as follows:
This is an inline image:
If you put an image on a row by itself, it will be rendered as a figure, with a figure caption. Example:

This becomes:
Flag of Chile
You can also define multi-resolution images as follows. In HTML, they are rendered using the <picture> element.
Now, the browser will select the most appropriate image, based on available space, if the browser supports responsive images based on the <picture> element. This is how it will look in your browser:
Banner
In the same way, you can also define multi-format images using reference notation. You simply list the media items and their different resolutions, if availble one after the other, optionally on separate rows.
<img> elements are used in HTML to display an image.
Multi-resolution images are encapsulated in <picture> elements, where each image is made available in a separate <source> element.
If the image is alone on a paragraph, it is furthermore encapsulated in a <figure> element, and its caption in a <figcapton> element.
Video
You can insert video content into your markdown documents, as you would insert images. The file extension is used to identify the content item as video. When publishing video on web pages, it’s important to remember that different clients have support for different video container formats and codecs. For this reason, it’s recommended to publish multi-format video so that the client can choose the stream that best suits its capabilities. Example3:
You can also insert audio content into your markdown documents. The file extension is used to identify the content item as audio. When publishing audio on web pages, it’s important to remember that different clients have support for different audio container formats and codecs. For this reason, it’s recommended to publish multi-format audio so that the client can choose the stream that best suits its capabilities. Example4:
Note: This will not be visible in the browser, but will cause it to play the sound when the page loads, if sound is supported. Audio clips will not loop.
YouTube
To include YouTube clips into your document is easy. A YouTube multimedia content plugin recognizes the YouTube video URL and inserts it accordingly into the generated page inside an <iframe> element. Example:
You can embed external web content in an <iframe> by using the multimedia inclusion syntax. If the content points to a text page (HTML included), or the resource ends with /, and no other multimedia interface provides a better match, the content is embedded as a web page. Example:

This becomes:
Note: You can’t embed local markdown this way, since it will be included directly into the document, as described below.
Table of Contents
Inserting a Table of Contents into your document is easy. It’s compiled automatically from all headers in the document. To insert it, you simply write the following where you want it inserted. This segment is taken from the Table Of Contents shown at the top of the page.

Note: If a page only contains one level 1 header, it’s considered a page title, and not included in the table of contents.
Markdown inclusion
It is possible to include other local markdown documents directly into the flowing text of the current document. This is done by loading the document, parsing it and generating the corresponding output in the same place where the inclusion was made. This makes it possible to create reusable markdown templates that you can reuse from your whole site. It also allows you to create output that would not be possible using normal markdown syntax. You can also pass parameters to the referenced markdown documents using query parameters in the local URL.
Note: Remember that the inclusion paths of the markdown content you want to include, are relative to the location of the main markdown file. The system will detect circular references and return an error if you try to create a document that creates such a circular reference. Also, included markdown files must not contain any metadata.
Note 2: Script parameters can be either double, boolean or string values. If the value cannot be parsed as a double or a boolean value, it is taken to be a string. Any further parsing must be done by script in the template.
Script
Script can be used to make your markdown pages dynamic. The following sections describe different options. For more information about script, see the Script reference. You can also use the Prompt to experiment with script syntax.
Script in Markdown can be processed in three different ways:
Inline processing: The script is evaluated as part of rendering, and the result presented in the place of the script.
Pre-processing: Script is evaluated prior to rendering the page for display. This allows script to modify the structure of the Markdown document.
Asynchronous processing: Long-running script can be run asynchronously. This means the page is rendered and returned to the client. When the script is evaluated, it is returned to the client, which inserts it in the place of the script.
Inline script
Script can be embedded inline in a block, between curly braces { and }. The result is then presented in the final output. Example:
*a* is {a:=5} and *b* is {b:=6}. *a*\**b* is therefore {a*b}.
This becomes:
a is 5 and b is 6. a*b is therefore 30.
Note: Inline script must all reside in a block. While new-line can be used in such inline script, empty rows separating blocks cannot.
Graphs
If you use inline script, the result may control how the data is output. Normally, strings are inserted. But graphs and images can also be generated in script. In these cases, they are displayed directly. Example:
Pre-processed script is inserted into the markdown page between double curly braces {{ and }}. Such script is evaluated before parsing the markdown, and the script is replaced by the result, as strings. Normal inline script between single braces are evaluated after markdown processing, and can contain any type of result. Such script does not change the structure of the markdown document. Pre-processed script however, can change the actual structure and formatting of the document.
Example:
Result of execution: {{s:="some text";"**"+s+"**"}}.
This is transformed to:
Result of execution: some text.
Loops and dynamic content
You can use the implicit print operation in script to dynamically fill the document with contents available though script. This makes it possible to create dynamic documents with markdown, and not only static ones. The basics consists of defining the script as a pre-processed script block, and implicitly printing the contents. The following example illustrates this point, by creating a multiplication table:
| \* |{{
for each x in 1..15 do
]] ((x)) |[[;
]]
|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|[[;
for each y in 1..15 do
(
]]
| **((y))** |[[;
for each x in 1..15 do
]] ((xy)) |[[;
)
}}
*
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
1
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
2
2
4
6
8
10
12
14
16
18
20
22
24
26
28
30
3
3
6
9
12
15
18
21
24
27
30
33
36
39
42
45
4
4
8
12
16
20
24
28
32
36
40
44
48
52
56
60
5
5
10
15
20
25
30
35
40
45
50
55
60
65
70
75
6
6
12
18
24
30
36
42
48
54
60
66
72
78
84
90
7
7
14
21
28
35
42
49
56
63
70
77
84
91
98
105
8
8
16
24
32
40
48
56
64
72
80
88
96
104
112
120
9
9
18
27
36
45
54
63
72
81
90
99
108
117
126
135
10
10
20
30
40
50
60
70
80
90
100
110
120
130
140
150
11
11
22
33
44
55
66
77
88
99
110
121
132
143
154
165
12
12
24
36
48
60
72
84
96
108
120
132
144
156
168
180
13
13
26
39
52
65
78
91
104
117
130
143
156
169
182
195
14
14
28
42
56
70
84
98
112
126
140
154
168
182
196
210
15
15
30
45
60
75
90
105
120
135
150
165
180
195
210
225
Asynchronous processing of script
It is possible to execute script on the page asynchronously as well. This is done by adding a Code Block of type async. The async can be succeeded by a colon (:) and some text that will be displayed while the script is being executed and the result loaded to the client. You can use the preview function to display a partial result during the calculation. Example:
This generates the following result (reload to restart):
Previewing intermediate results
Note: If the script returns XML, and there is an XML Visualizer available in the code (i.e.a class that has implemented Waher.Content.Markdown.Model.XmlVisualizer), the XML is first transformed before being visualized. For example, script may compute a 2D Layout XML document, that is then used to generate a visual image, as shown in the following example:
When a user connects to the server, it will receive a session. This session will maintain all variables that is created in script. These variabes will be available from any page the user views. Each user will have its own set of variables stored in its own session. If the user does not access the server for 20 minutes by default, the session is lost, and any variables created will be lost.
Query parameters
When loading a markdown page, any query parameters listed using the PARAMETER metadata tag will be available as variables in script. If the query variable is not available, the parameter will be set to the empty string. By default, the variable type is a string, unless it can be parsed as a double number or a boolean value.
Global variables
When a user session is created, it will contain a variable named Global that points to a global variables collection. The global variables collection and the session variables collection can be used by resources to keep application states. States will be available for all script on the server, if accessed through the Global variables collection.
Example:
This page has been viewed {Global.NrTimesMarkdownLoaded:=exists(Global.NrTimesMarkdownLoaded) ? Global.NrTimesMarkdownLoaded+1 : 1} times since the server was last restarted.
This becomes:
This page has been viewed 144 times since the server was last restarted.
Note: If the count does not increment when the page is loaded or refreshed, it means you’re receiving a cached result. You can control page cache rules using Metadata tags.
Page-local variables
When navigating on Markdown pages, a page-local collection of variables is available, by referencing the session variable named Page. Every time a new page is viewed by the same session, the Page-collection is cleared. The Page collection can be a good place to store temporary information related to the current page.
Example:
This page has been viewed {Page.NrTimesMarkdownLoaded:=exists(Page.NrTimesMarkdownLoaded) ? Page.NrTimesMarkdownLoaded+1 : 1} times since you last navigated to this page.
This becomes:
This page has been viewed 1 times since you last navigated to this page.
Current request
The session state will contain a variable named Request that contains detailed information about the current request. The variable will contain an object of type Waher.Networking.HTTP.HttpRequest.
Current response
The session state will contain a variable named Response where the response is being built. The variable will contain an object of type Waher.Networking.HTTP.HttpResponse. It can be used to set custom header information, etc.
Posted data
Data posted to a page can be accessed, in decoded form, by accessing the Posted variable, defined in the Waher.Networking.HTTP module. This makes it possible to implement a form into a Markdown page, and process posted information from script embedded in the document itself, or linked to it in the meta-data headers.
Web Services
There are multiple ways to define web services using Markdown and/or script, as outlined in the following sub-sections.
Web Script
Web Script (Web Service, or Waher Script) is script that is stored in files with extension .ws. A client can POST data to such a Web Script file. The data will be decoded and made available in the script through the Posted variable. The result of the script is then encoded to the client, based on the Accept header in the HTTP Request. For JSON responses, the Accept header should have the value application/json.
Markdown-based Services
You can create separate Markdown files with the BodyOnly meta-data tag set to true, to create web services that return HTML directly. This is suitable if the response does not need to be parsed and conditionally processed, but only displayed to the user. A client POSTs data to such a Markdown file. The data will be decoded and made available in the script through the Posted variable. The result of the script is then encoded to the client, based on the Accept header in the HTTP Request, which should be text/html.
Generation of JavaScript
The Markdown engine can generate JavaScript for you automatically, facilitating the dynamic creation of items on web pages. This conversion can be done either by specifying an Accept: application/javascript header when requesting for a Markdown file, or by referring to a Markdown file with an additional .js extension after the traditional .md extension. Referring this way to a file Test.md.js for instance, will generate a JavaScript rendering of the Test.md file. This method is useful if referring to JavaScript files from the header of an HTML file, for instance, where you cannot control the browser’s selection of HTTP Accept header field in the request.
When converting a Markdown file (for example Test.md) to JavaScript (for example Test.md.js), two functions are created and included in the file:
function CreateHTMLTest(Args);
function CreateInnerHTMLTest(ElementId, Args);
The final Test in the funcion names are taken from the name of the Markdown file being converted. This makes it possible to include multiple JavaScript files generated from multiple Markdown files on the same page. The Args argument can be used to send information to the function, which is later used by inline script when generating HTML.
The first function returns a string containing the HTML generated by the JavaScript. The second function calls the first function to generate HTML, the looks in the DOM of the page to find an element with a given id attribute, and then sets the innerHTML property of that element to the generated HTML.
Things to keep in mind when converting Markdown to JavaScript:
Script placed between double braces {{ and }} is preprocessed on the server and affect the structure of the Markdown, which in turn affects the generated JavaScript. Such script do not have access to the Args argument. Instead they have access to any session variables that may exist.
Script placed between single braces { and } is not processed on the server at all. Instead, it is assumed to be JavaScript itself, and inserted as-is into the JavaScript. This allows you to populate the dynamic HTML using values from your browser, without having to request the server to do it. This also means, that the script syntax normally used for single-braces evaluation on the server, is not used in the JavaScript case. The inline script has access to Args, but as it runs in the browser, does not have access to server-side session-state variables.
If the Markdown only contains a header-less table (i.e. a table with zero header rows), the JavaScript rendered will only generate the table rows, not the surrounding table, thead and tbody elements, to facilitate dynamic addition of rows to a table.
Generated JavaScript Example
Consider the following Markdown page, saved as Test.md:
JavaScript: TestTable.md.js
Title: JavaScript generation test
Description: This page displays a table dynamically generated by JavaScript, rendered from a Markdown template.
AllowScriptTag: 1
JavaScript generation Test
-----------------------------
The following table was generated by JavaScript:
<div id="TestTableLocation"></div>
<script>
CreateInnerHTMLTestTable("TestTableLocation", {"A": 5, "B": 7});
</script>
It refers to a Markdown template called TestTable.md, in a JavaScript header. To make sure the server converts this Markdown to JavaScript, the extension .js is added to the filename, resulting in a reference to TestTable.md.js file. When the browser requests this file, the server recognizes that the file does not exist. Instead, it recognizes the .js extension, understands that it refers to the Accept: application/javascript header, and modifies the request to refer to TestTable.md with the corresponding Accept header set. The server then loads the Markdown, converts it to JavaScript, and returns JavaScript that generates HTML from the following Markdown template:
The first block in a markdown document has the option to be a metadata block. Such a block is not directly visible on the page, but is used to provide metadata information to the parser, search engines and other entities loading the page. Metadata is provided in the following form:
Key1: Value 1
Key2: Value 2
...
Apart from providing metadata information about the page, you can access the metadata information from your page by using the [%Key] operator. That operator will be replaced by the value of the korresponding key. Example:
The title of this document is "[%Title]". It describes [%Description]
It was written [%Date] by [%Author].
This is then transformed to:
The title of this document is “Markdown”. It describes Markdown syntax reference, as understood by the TAG Neuron. It was written 2016-02-11 by Peter Waher.
Note: If a metadata record does not exist for a given key, but a variable exists with the given name, the corresponding variable value will be inserted instead.
The following subsections list the different metadata keys that have special meaning to the TAG Neuron Markdown parser. You’re not limited to these metadata keys, and can freely add your own.
AllowScriptTag
If the <SCRIPT> tag should be allowed or not. Value is a boolean value. Strings representing true, include 1, true, yes and on. Strings representing false, include 0, false, no and off.
Default value, if not provided, is false.
Alternate
Link to alternate page.
AudioAutoplay
If audio should be played automatically or not. Value is a boolean value. Strings representing true, include 1, true, yes and on. Strings representing false, include 0, false, no and off.
Default value, if not provided, is true.
AudioControls
If audio should be played automatically or not. Value is a boolean value. Strings representing true, include 1, true, yes and on. Strings representing false, include 0, false, no and off.
Default value, if not provided, is false.
Author
Write the name of the author or authors using this tag.
BodyOnly
If only the contents of the body should be returned or not. This is useful if you create dynamic pages using the XmlHttpRequest object (AJAX), as it removes the DOCTYPE and header (and body tag) from the response, and only returns the corresponding HTML content. Value is a boolean value. Strings representing true, include 1, true, yes and on. Strings representing false, include 0, false, no and off.
Default value, if not provided, is false.
Copyright
Allows you to provide a link to a copyright statement.
CSS
Links to Cascading Style Sheets that should be used for visual formatting of the generated HTML page.
Date
Provide a date for when the document was created. This date is presented in the metadata header of the document. The web server uses the last write date of the file to tell clients when the file was last updated.
Description
Provides a description for the page. This description is shown to search engines and other clients, and should contain a short description of the page motivating people to view your page.
Details
Points to the place in a master document, where the details section is to be inserted. The [%Details] operator differs from the other meta reference tags, in that it can stand alone in a separate block.
Help
Link to help page.
Icon
Link to an icon for the page.
Image
Link to an image for the page.
Init
Links to server-side script files that should be executed before processing the page. The script is only executed once, regardless of how many times the markdown page is processed. It can be used to initialize the backend appropriately. To execute the script again, a newer version must be available. The file time stamps are used to determine if a file is newer than a previous version or not. For script that is to be executed every time the page is processed, see the Script tag.
JavaScript
Links to JavaScript files that should be included in the generated HTML page.
Keywords
Here you can provide a set of keywords describing the contents of the document.
Login
Link to a login page. This page will be shown if the user variable does not contain a valid user.
Master
Points to a master content file that embeds the current file in a [%Details] section (if written in Markdown).
Next
Link to next document, in a paginated set of documents.
Parameter
Name of a query parameter recognized by the page. Any query parameter values for parameters listed in the document will be available in script. If the query parameters are missing, the corresponding parameters will be set to empty strings. By default, all parameters are strings, unless they can be parsed as a double number or boolean value.
Previous or Prev
Link to previous document, in a paginated set of documents.
Privilege
Requered user privileges to display page. Meta-data tag can be used multiple times, one for each privilege required. The IUser.HasPrivilege method (defined in Waher.Security) will be called to check that the valid user has the corresponding privilege, before the page is displayed.
Refresh
Tells the browser to refresh the page after a given number of seconds.
Script
Links to server-side script files that should be included before processing the page. Script linked to here will be executed every time the markdown document is processed. For script that is to be executed only once, see the Init tag.
Subtitle
Provides a means to create a subtitle for the document. If provided, will be shown, together with the title, in the browser header or tab.
Title
Use this key to provide a title for the document. The title of the page will be shown in the browser header or tab.
UserVariable
Name of the variable that will hold a reference to the user object for the currently logged in user. If privileges are defined using the Privilege meta-data tag, this user object must implement the IUser interface (defined in Waher.Security). If multiple UserVariable meta-data tags are defined, the first one that is found will be used.
VideoAutoplay
If video should be played automatically or not. Value is a boolean value. Strings representing true, include 1, true, yes and on. Strings representing false, include 0, false, no and off.
Default value, if not provided, is false.
VideoControls
If video should be played automatically or not. Value is a boolean value. Strings representing true, include 1, true, yes and on. Strings representing false, include 0, false, no and off.
The value of this tag will be used when returning the document over an HTTP interface. The value will be literally used as a Cache-control HTTP header value of the generated HTML contents. Together with the Vary meta-tag they provide a means to control how the generated page will be cached.
Note: If the markdown page is dynamic, and no Cache-Control metadata header is present, the following HTTP header will be added automatically:
Cache-Control: max-age=0, no-cache, no-store
If the markdown page is static, and no Cache-Control tag is present, the following will be used:
HTTP Sunset Header allows you to flag content for removal at a future point in time. It allows clients to prepare.
Vary
The value of this tag will be used when returning the document over an HTTP interface. The value will be literally used as a Vary HTTP header value of the generated HTML contents. Together with the Cache-Control meta-tag they provide a means to control how the generated page will be cached.
 ,
,